I’ve written some serial dilution code and I think something to keep in mind is that you want to transfer 1 to 2, dilute 2, transfer 2 to 3, dilute 3, etc. I did this using transfer_plate (Plate object or trough/reservoir) and diluent_plate (usually a trough/reservoir of some kind). Not sure if this is already in the code, but just a thought.
Serial dilution command I’m not so sure about: sounds useful but different people might dilute differently?
aliquot command → Yes!
One step further: I think we should expose all open-source Opentrons commands to PLR.
This includes:
transfer - astonishingly useful because it autogenerates transfer cycles based on the max vol of a tip: lh.transfer(source=tube_a, desination=tube_b, vols=[4_200]) → would require chunking the volume into separate transfers of [1000, 1000, 1000, 1000, 200] transfers with a tip_1000ul; differently with a tip_300ul
distribute / “aliquot” - one source multiple destinations = the backbone of normalisations
…the fun part I have been meaning to find the time to develop for a while: evolve “LiquidClass” into what I propose we call LiquidTransferManager() - a Python class that adjusts all transfer parameters dynamically, the evolution of “LiquidClass” and a real Python class storing data and functionality to make these complex commands accurate.
Building the verification tool for LiquidTransferManager() will be a beast
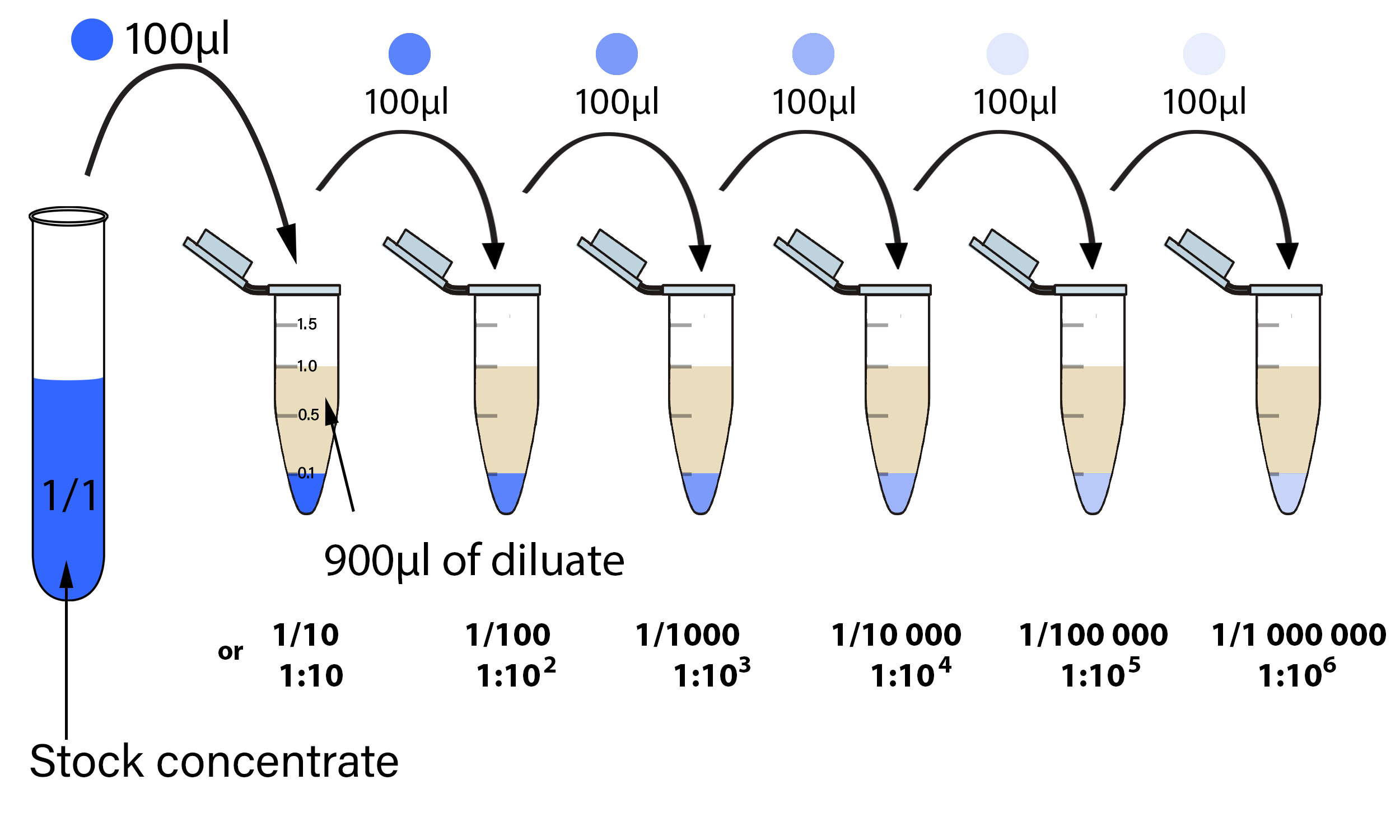
the one time i did serial dilution in undergrad, every tube was already filled with diluent and you just needed to transfer transfer and mix. the first tube was filled with the compound of interest at the start (before this method is called)
I’ve implemented a serial dilution calculator that takes in dilutions as % and desired final volumes that could be passed into the aspirate and dispense functions. useful for us! but you’re right may not be universal
I’d need to look more into the current implementation.
…but does the current implementation enable one aspiration → variable volume dispensations with each dispense taking a different “parameter set” + pre-dispense vol for the first dispense going back into the source Container + retention_vol (the vol retained at the end of the distribution/aliquoting)?
in terms of pipetting, is it different from what the picture above? potentially useful to expose some utils to compute volumes as a util, but in terms of the LH method are there multiple ways people conventionally make dilutions? i am only familiar with this method i showed
not such fancy parametrization. Not all may be possible in a higher level method because the method would get extremely complex. But I am considering keeping aspirate/dispense available in LiquidHandler so people have lower level control for complex operations.
it does the one aspiration, and right now fixed volume dispensation but I suppose we could do variable volume dispenses
sorry im not sure i understand. in the example above, each tube starts off with say 900 uL of diluent. The first tube has 900uL of diluent and 100uL concentrate. Then, 100uL of the mixed contents of the first tube (10% concentration) is taken out and put into tube 2, which then has 100uL at 1%. Take 100uL of tube 2 to make 0.1% in tube 3. Each transfer is the dilution? I’m not sure what the difference is between dilution step and transfer for you. (not a biologist, i’m just building on biochem 101)
Does it, i.e. lh.aliquot, take at least one “LiquidClass” and hands it down to the 1xaspirate & n xdispense operations?
Distribution (as Opentrons calls this operation, which is a clearer name in my view) absolutely requires “pre-dispense” and “post-dispense” volumes packed into the commmand:
I’ve seen this implemented even on simple electronic pipettes (e.g. from Sartorius).
And Hamilton has actually a pretty good guide on the topic: Hamilton: Liquid Handling Best Practice - Multi-Dispensing (Aliquot)
…explaining…
But, with programmatic/procedural control of our liquid handling systems - thanks to PLR - we can make our machines figure out the complex parameter setups autonomously, making these complex commands, for the first time, really usable AND reliable.
I completely agree: it is a very complex implementation. But people writing automated protocols using PLR choose it because of the power of programmatic control (I believe - would be interested to have another poll on this actually…).
So complexity is what I expect, and PLR is the tool to solve it
Could be useful. I’ll second about the Opentrons transfer API though - it can do a lot of these things very easily. For example, for your serial dilution:
[p20m.transfer(10, plate.wells_by_name()[["A1","A2","A3"][x-1], plate.wells_by_name()[["A1","A2","A3"][x], new_tip="always") for x in [1,2]]
Built into that transfer, you can get things like mixes in-between (before or after), or new tips (which DNA WILL stick to your pipette tips when doing serial dilutions, been testing that one out), or anything else. Becomes a little more powerful.
To me, higher level functions like aliquot and serial dilute take mental load (gotta remember all those functions), but don’t expose significantly more functionality per line of code. Whereas something like the transfer function does. That said, I actually usually just aspirate/dispense within my own Opentrons code manually because I like knowing EXACTLY what will happen and it being written out.
If the first tube has 1000 uL (1 mL) of 10%, moving 100 uL of 10% just results in 100 uL of 10% in tube 2. must add 900 uL diluent to tube 2 to get it down to 1%. We do funky dilutions (e.g a series of 48%, 40%, 32%, etc.) so it’s not the same transfer and diluent volume each time which is why I have the additional calculation step.
from an api design perspective, I disagree. I think one super function with impossible types and unclear syntax is confusing to users. With specialized functions, every function implementation is easy to read. It is easy to know how each function should be called. In addition, for scientists they can easily read aliquot and serial_dilute.
For one user, the super function will be a magical solve-all and to the second user it doesnt do that they want.
With complicated methods, you have to be really careful about the user being able to express impossible actions or there being two ways to express one action. For example, in ot2 transfer, the type for source and well is AdvancedLiquidHandling which is not even documented anywhere. Search — Opentrons Python API V2 Documentation
But yes, aliquot and serial_dilute are easy to express in 1:1 well transfers as well. These two composite methods are just higher level utilities.
is this a common way of doing it? is it reason to not have a serial_dilute function like i made for this pr? i have little intuition on this level, so would like to hear everyone’s opinions
I think one super function with impossible types and unclear syntax is confusing to users
Hmmm, yeah I guess this makes sense. I’ve gotten used to it and as a power user it is convenient (the impossible types and unclear syntax aren’t mysterious anymore), but you’re right that functions generally shouldn’t be everything and the kitchen sink (even if this is python). I’ve been personally a fan of just writing out everything individually lately.
is it reason to not have a serial_dilute function like i made for this pr?
Explicit or non-explicit tip usage is pretty important to have, I think. Often when I need approximate dilutions (think, cell transformation) I’ll skip using a new set of tips to save time + tips + deck space, but there are other times when I really need those new tips. It is also not clear to me the quantity of mixing and at which step it is happening at (if the mix before pipetting? After pipetting? Why for each?)
Also, for the aliquot function - often I will pull up multiple wells plus dead volume - ie, if I have a p300, I might pull up 50uL 5x times plus a dead volume of 30, then aliquot that number of times. Makes it so you don’t have the pipette travel time back to source, which definitely starts adding up.
The goal is definitely to write PLR for power users.
i was thinking about adding a tip_generator param (generator). If None, it will use the tips picked up before the method is called. Otherwise get them from the tip generator.
the current aliquot draft implementation supports this. (That is the point of having a function rather than just 1->1 transfer.) It also goes back to aspirate more when needed. As for mixing, I think this should be done through {Aspirate,Dispense}Parameters as Camillo wrote about above.