Slightly random question (and could also be naive since I am a new Hamilton user).
We recently bought a used STARlet and I was given best practice instructions to run the daily and weekly maintenance macros to keep the robot in tip-top shape. As far as I know, it stretches/homes the arms and uses the teaching tips for pressure/cLLD testing. Might be doing some other things too - haven’t looked through the log files in detail.
we don’t have this (yet). i don’t know how useful it is (it could be useful, really just don’t know). we actually never run maintenance, or any other script before/after a run
We run it daily; every morning before production occurs. When you have a fleet and scientists are on deadlines you can catch mechanical failures that would potentially happen during a live sample run. Only happens once in a blue moon, but enough that we never skip.
I figured it was a useful preventative maintenance step for machines with heavy use - good to hear it is useful! Do you use the provided macros or have you crafted your own?
We don’t use PLR on our production, so don’t feel like you have to add it for me lol. This is more of my interest on the side. Unfortunately we need the “validated” Venus software for our production instruments.
The daily also does a pressure check on the channels to make sure the o-rings aren’t in bad shape and need replacement.
Hi @cwehrhan,
Thank you for the explanation. Can you give us some details of what kind of errors/machine failures the daily/weekly maintenance routines detect and how you solve them?
From my (most likely incomplete) understanding the routines simply perform some simple sensor measurements for a given set of instructions and checks that these measurements fall into a given, predefined range.
e.g. the cLLD probing with the teaching needles appears to test both the cLLD detection capabilities, and (I hope) the gantry tilt, i.e. how far it expects the channel to move in the z-dimension until it detects the waste-wall.
I believe you are right: based on the logging of the maintenance protocol this would be very easy to implement in PLR.
The question is just: What do you do if the parameters measured deviate from the expected values?
if script_mode == 'execution':
await lh.backend.move_all_channels_in_z_safety()
if not lh.backend.core_parked: # return grippers
await lh.backend.put_core()
# discard tips if any are present
has_tip_check = [lh.head[idx].has_tip for idx in range(8)]
if any(has_tip_check):
await lh.discard_tips()
await lh.backend.spread_pip_channels()
# Stop temperature control
try:
await lh.backend.stop_temperature_control_at_hhs(1)
except Exception as e:
print(f"An error occurred while stopping temperature control:\n{e}")
# Stop temperature control
try:
await lh.backend.stop_temperature_control_at_hhc(2)
except Exception as e:
print(f"An error occurred while stopping temperature control:\n{e}")
await lh.stop()
# close_camera()
This doesn’t really “home” the channels in the same way that the channel initialisation homes them.
But the channel initialisation is anyway executed when you start a new automated protocol via the lh.setup() call.
What this does is just make sure your deck is ready for the next script, i.e. “clean up” the deck
(if you don’t control an HHS or HHC via the STAR connection, then just delete those lines; leaving them shouldn’t break the code snippet but it’s just unnecessary then)
Lots of autoload errors -the hall effects sensor on the front of the autoload loves to move around. We also use static decks, so if something is not seated all the way we can catch that then, it hits the autoload lol
“Clanking of channels” when things are out of alignment you can hear it, if its in the Y on the 1000ul, they’ll slap into each other.
Clean up the deck if scientist left things accidently
The next few are more rare but we have caught:
Rarely tip pick up failures
Firmware errors, which indicates the motors are bad or some hardware is failing
A lot of it also if something goes wrong we can verify that the instrument hardware wise was performing that morning, so we can isolate it to a software issue easier, aka you programmed your method wrong and a scientist caught an edge case. That way going into trouble shooting you know the instrument was operational that day. Also makes the Scientific teams happy to know it passed daily before they begin their work. I’ll admit it doesn’t really do much but even a small reassurance that the instrument is working can build trust.
We log all of the errors that ever occur on the instruments for service, and pipe this into an aws bucket for analytics. We’ll get random hardware errors that sometimes resolve after a reboot but good to keep track of, incase something is on the verge failing or intermittent. This include daily maintenance errors.
I do not believe that it checks the deck tilt, that’s something that can only be done in service software. For tilt you need a datum, the service tool has a little cnc’d box that works as a datum.
It would probably prompt some deeper maintenance or repairs. As a user, I would want to double check protocols run since the previous maintenance protocol to see if anything looks abnormal (in the same vein that @cwehrhan said it builds trust in the equipment)
Thanks for sharing! So it looks like there are some backend methods to “reinitialize” certain heads without having to write methods using lh.move_channel_x (or y), etc. This is helpful, thank you!
We can look into maintenance procedures for PLR, getting machines accepted by pure wetlab bioscientists is important
… but instead of running them all separately, do you think it would make sense to integrate them directly into the machine setup command?
i.e. do you want to…
have a separate automated protocol that just checks the “maintenance status” / health check?
→ requires maintenance of the maintenance protocol(s)
OR
would you want to spend a bit more time at the beginning of every automated protocol that performs the health check of the machine every time you run an automated protocol (on a non-initialised machined)?
→ costs a bit of time at the beginning but removes the maintenance of the maintenance protocol(s)
Yes, PLR gives us access to the power of all commands that the manufacturer’s engineers invented (rather than those that a click and drop GUI gives us access to), enabling the entire world to mix & match these to generate re-usable solutions to problems one might encounter.
You can read more about the the backend methods of the STAR machines for setup/initialisation in pylabrobot/liquid_handling/backends/hamilton/STAR.py.
(Clarification to avoid nomenclature confusion:
I am using established programming language here: method == a function associated with a class - not the classic biowetlab automation engineer’s meaning of “method” == automated protocol)
Specfically, lines 1348 following (status: 2025-01-03) might be interesting to you:
initialized = await self.request_instrument_initialization_status()
if not initialized:
logger.info("Running backend initialization procedure.")
await self.pre_initialize_instrument()
if not initialized or any(tip_presences):
dy = (4050 - 2175) // (self.num_channels - 1)
y_positions = [4050 - i * dy for i in range(self.num_channels)]
await self.initialize_pipetting_channels(
x_positions=[self.extended_conf["xw"]], # Tip eject waste X position.
y_positions=y_positions,
begin_of_tip_deposit_process=int(self._traversal_height * 10),
end_of_tip_deposit_process=1220,
z_position_at_end_of_a_command=3600,
tip_pattern=[True] * self.num_channels,
tip_type=4, # TODO: get from tip types
discarding_method=0,
)
if self.autoload_installed and not skip_autoload:
autoload_initialized = await self.request_autoload_initialization_status()
if not autoload_initialized:
await self.initialize_autoload()
await self.park_autoload()
If you wanted to, you could just replace self with lh.backend (i.e. STAR) and then run this in your Notebook cell / Python code
i think it should be separate. It is up to the user to integrate it into their script, called after setup because setup is required to establish the usb connection and initialize the components. Running this as a part of standard operations is not strictly necessary (as is proven by currently working protocols) even though it is adding value as Colin explained. We could have something like STAR.run_diagnostics.
I’m coming from a pure Hamilton Venus world, not saying you have to do it like they do at all, but they do have some tried and true procedures that work.
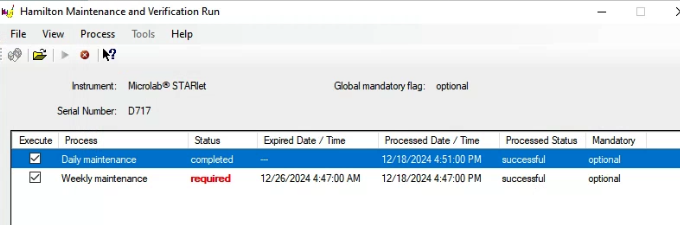
Daily/weekly maintenance is a separate application that compiles some fancy HSL (discovers what kind of deck it is automatically no deck attached). This sets a flag in the registry if daily/weekly was completed. This flag is then checked by Venus run control any time you want to execute a method. However in system preferences of Venus you can uncheck the box to check the registry, so it is possible to skip daily/weekly.
I don’ think you want to run daily maintenance in the setup command as you stated in option #2, that would take to long if I am debugging a protocol.
STAR.run_diagnostics would be cool. What about some persistent flag similar to the current daily? That might be over kill at this point, as it seems no one is using this right now, possibly a future scenario
Honestly, for my purposes this is something that would be very useful.
I’m currently working on an automated setup incorporating a Hamilton liquid handler that will be doing end-to-end runs without human intervention for potentially multiple days on end.
Hence, some capability to automate the running of the daily maintenance would be very welcome indeed!