following PLR Dev Roadmap 2025 - Q1 & Q2 - #2 by koeng?
The current PLR integration for OT is whack. At a high level it works like this:
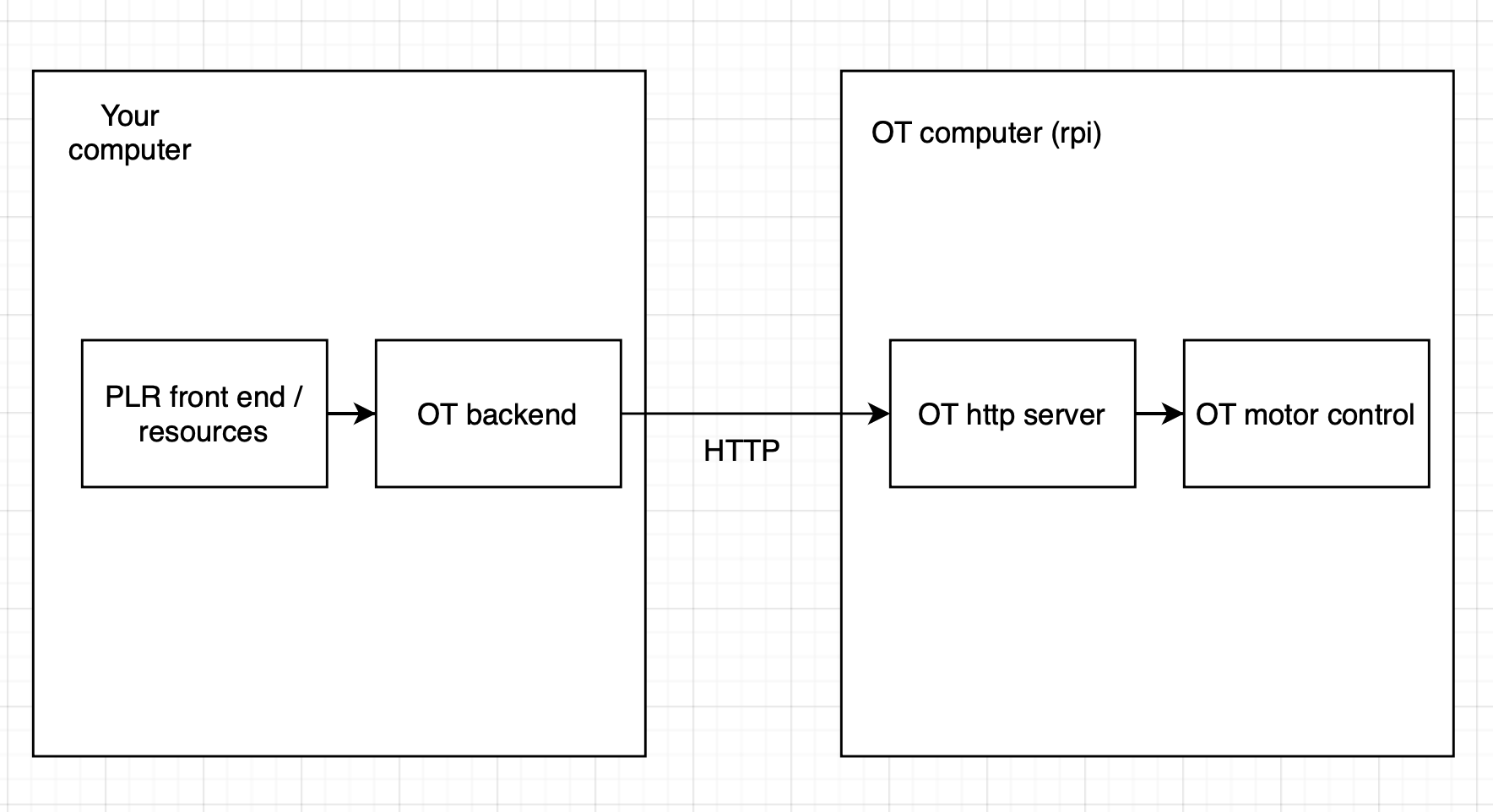
We use a slightly older version of the Opentrons HTTP API, through a python wrapper i wrote. when i wrote this, the OT required to have an internal model of resources. This required that every time a resource is defined in plr, we make a request to the ot saying “there is now a new resource named X that looks like this”. Operations like pickup tip / aspirate etc. send the name/identifier of a well rather than a location. Since the OT model is extremely constrained (resources have to follow a certain grid format) and there is/was no easy way to remove resources, the PLR integration with OT was bad. We could only use a subset of our resource model, and it was not editable at runtime.
Compare this to a STAR or EVO, where we can arbitrarily say “aspirate at xyz”. This is powerful, because we can manage the deck state and just tell the robot to execute operations at locations where we know containers/tips of interest are.
Recently I checked and saw that the OT api now supports manual channel movement and “aspirate in place”. PLR should migrate to this new api version. With this new version, we should no longer make requests to the OT onboard computer to tell it about resources and just manage everything in PLR. When it’s time to execute an operation, just move and do the operation in place. We get full flexibility to use the very accurate plr model, custom resources, etc. We can use our Retro $14 3d-printed tilt module.
In the past, using PLR with OT was a pain since you couldn’t use the benefits of PLR. Instead, it was actually worse in some ways because the HTTP API didnt express the full functionality of the machine. With this upgrade, PLR could be a better way to use the OT than the official python api.
As an alternative to using the new http api, it is also possible to write our own http server that would run on the OT onboard computer, like below. I initially considered doing this for the first implementation, but since we weren’t really using it and it wasn’t needed for proof of concept I decided against it. The benefit of this would be even more control (do we need it?). Arguably, we are less dependent on OT making changes, but we should still want to call into the OT stack at some point and there’s a risk they might change that. Also, the OT stack is complicated with many layers of abstraction that cross reference. If the new API is good, my vote would be going that way.
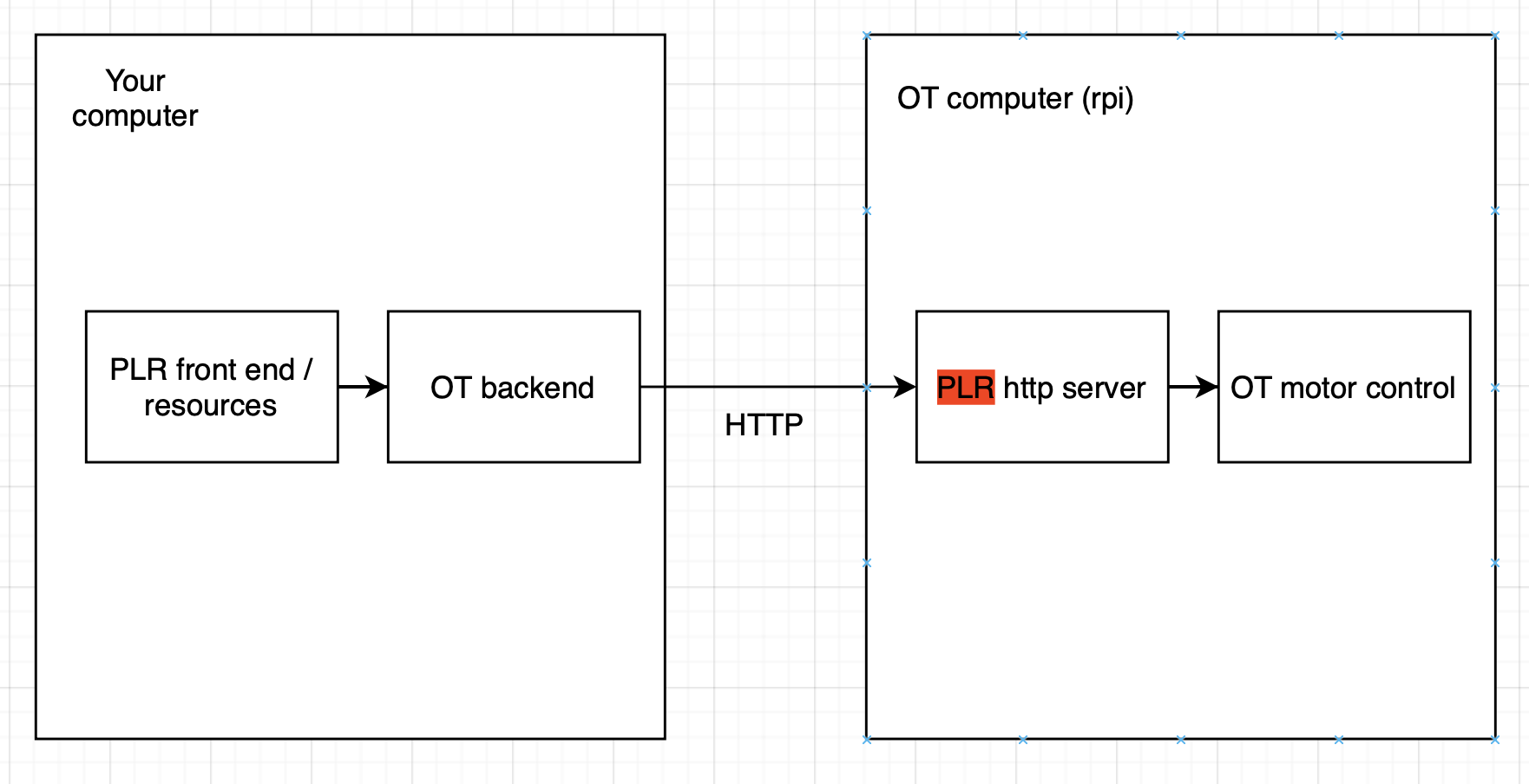
I might test and see if it’s easy to make this change one weekend, but it’s not a priority for me. Happy to discuss more or help someone else who’s willing to lead this project!